

지난 2023년 5월 10일, 구글 I/O 2023이 열렸다. 대중의 관심은 구글 픽셀 폴더와 픽셀 태블릿 같은 스마트 기기에 쏠려 있었지만, 구글은 달랐다. 생성 AI를 활용해 어떤 일을 할 수 있을지에 대해 120분 중에서 80분을 들여 이야기했다. 구글은 초조하게, 다음 변화도 우리가 주도할 테니 믿고 기다려 달라고 이야기하고 있었다. 구글이 초조해졌다니 대체 IT업계에 무슨 일이 일어나고 있는 걸까.
구글, 생성 AI의 서막을 열다
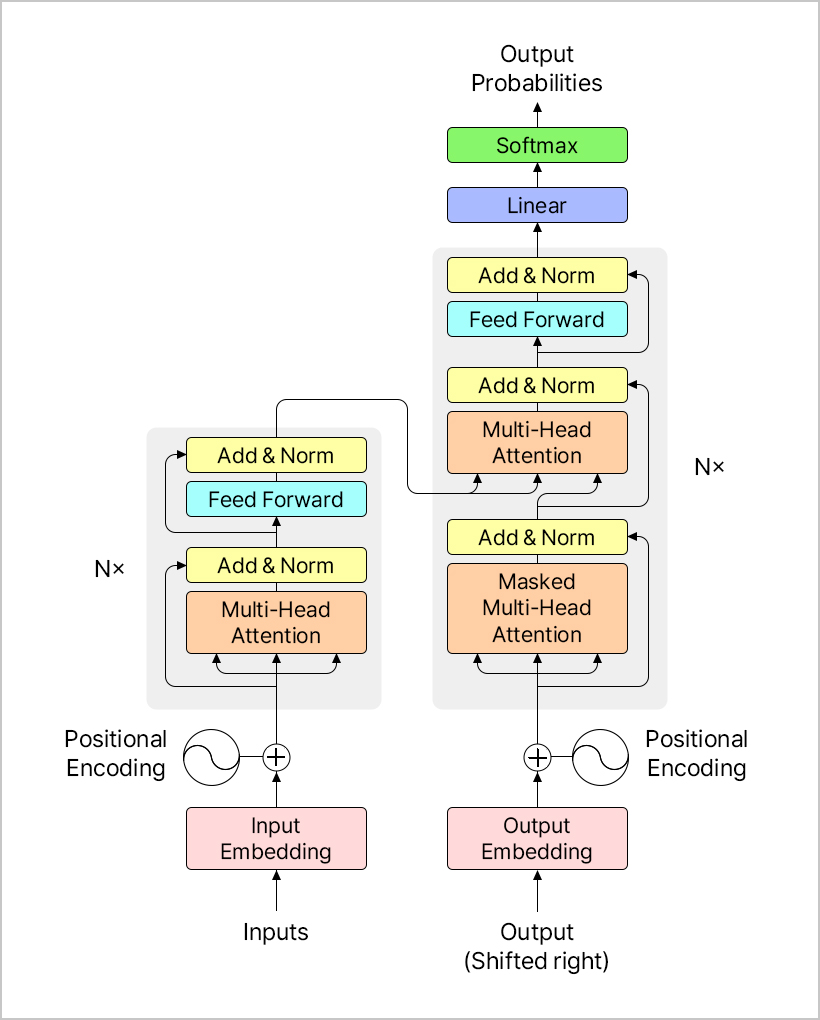
구글이 초조하다. 아이러니하지만 지금 같은 상황을 만든 건 구글 본인이다. 2017년 발표한 논문 < Attention is All You Need >가 시작이었다. 여기서 소개한 ‘트랜스포머 모델’은 기존 AI 모델보다 인간의 언어를 훨씬 빠르게 처리했다. 덕분에 우리가 일상적으로 사용하는 말을 컴퓨터가 읽고 듣고 이해하는 자연어 처리 분야(Natural Language Processing, NLP)의 혁신을 이끌었다.
성능이 너무 좋아서 2018년부터 트랜스포머 모델에 기반한 작업이 속속 공개됐다. 구글에서 만든 버트(Bidirectional Encoder Representations Transformers, BERT), 비영리 AI 연구소였던 오픈AI가 글을 만드는 데 특화된 GPT(Generative pre-trained transformers)를 공개한 것도 같은 해다. 2019년 오픈AI의 GPT-2, 메타(구 페이스북)의 RoBERTa가 공개됐지만, 반응이나 쓰임새는 미미했다. 구글은 AI의 최강자고 누구도 따라잡을 수 없을 것 같았다.

그러다 이런 흐름이 흔들리기 시작했다. 2020년 6월, 오픈AI는 아주 매끄러운 문장을 만들어내는 GPT-3를 발표했다. 이전 모델보다 학습 데이터 크기가 두 배 이상 늘어났고 정말 그럴듯한 글을 만들어냈다. 많은 데이터를 처리하는 컴퓨팅 파워를 쓰는 데 너무 큰 비용이 들기에, 오픈AI는 MS로부터 클라우드 서버 이용비를 투자 받아 이를 극복했다.
GPT-3가 내놓은 결과물은 극적이었다. 덕분에 발표 후 수많은 찬사와 논쟁이 만들어졌다. 에세이를 쓰거나 의학 질문에 답하거나 소프트웨어 프로그램을 코딩하거나 복잡한 문서를 요약하는 등의 쓰임새도 모두 이때 태어났다. 특정 질문에 편향을 가진 대답을 하거나 그럴듯한 거짓말을 하거나 가짜 뉴스를 쉽게 만드는 등의 부작용도 이때 모두 지적된 일이다. 다만 한정된 사람만 쓸 수 있었기에 찬사와 논쟁도 관계자들 사이에서만 이뤄졌다. 이때까지만 해도 생성 AI가 어떤 일을 일으킬지 아무도 몰랐다.
마이크로소프트의 근거 있는 도발

오픈AI가 만든 이미지 생성 AI인 달리(DALL-E)는 2021년 1월, 달리2는 2022년 4월에 공개됐다. GPT-3를 기반으로 단어나 문장을 입력하면 이미지로 만들어주는 AI 모델이다. 같은 해 9월부터 누구나 이용할 수 있게 되면서 이미지 생성 AI가 붐을 일으켰다. 2022년 7월 출시된 생성 AI 소프트웨어 미드저니는 더 많은 화제가 됐다. 정말 그럴듯해 보이는 이미지를 만들어 주는데, 2022년 9월에는 콜로라도 주립박람회 미술대회의 디지털 아트 부문에서 미드저니로 만든 그림 <스페이스 오페라 극장(Theatre D'opera Spatial)>(제이슨 M. 앨런)이 1위를 차지하기도 했다. 이미지 생성 AI 시대를 본격적으로 연 주인공은 2022년 8월 출시된 스테이블 디퓨전(Stable Diffusion)이다. 누구나 쓸 수 있게 공개한 데다 개인용 컴퓨터에서도 돌릴 수 있게 최적화됐기에 수많은 사람들이 생성 AI에 뛰어들게 했다.

생성 AI로 제작한 광고 이미지나 스마트폰 게임 등이 쏟아지며, 시장의 판도가 바뀌기 시작했다. 이 같은 현상을 보고 오픈AI는 별로 유용하지 않다고 판단해 공개를 접을 생각이었던 GPT 모델을 일반인도 쓸 수 있게 ‘챗GPT’란 이름으로 오픈하게 된다. 서랍에 들어갈 뻔했던 챗GPT가 그렇게 세상에 모습을 드러냈다. 아는 사람만 알던 생성 AI가 갑자기 누구나 써 볼 수 있는 서비스로 변신했다.
챗GPT가 가진 ‘그럴듯한 문장을 만들어내는 능력’은 순식간에 이용자의 마음을 사로잡았다. 이런 분위기를 타고 오픈AI에 투자해 독점적 권리를 확보한 마이크로소프트가 발 빠르게 움직였다. 안 그래도 스마트폰에 뺏긴 점유율을 되찾기 위해 윈도우 OS에 심어 놓은 MS 엣지 브라우저와 빙(Bing) 검색을 수년간 밀어주고 있던 터였다. 2023년 1월, MS는 오픈AI에 100억 달러를 추가로 투자하고 장기적인 파트너십을 맺기로 했다. 그리고 2월에는 챗GPT를 탑재한 빙을 내놨다. 빙과의 채팅은 MS가 만든 엣지 브라우저를 이용할 때만 쓸 수 있도록 했다. 한마디로 구글의 밥그릇을 건드린 것이다.
구글의 반격
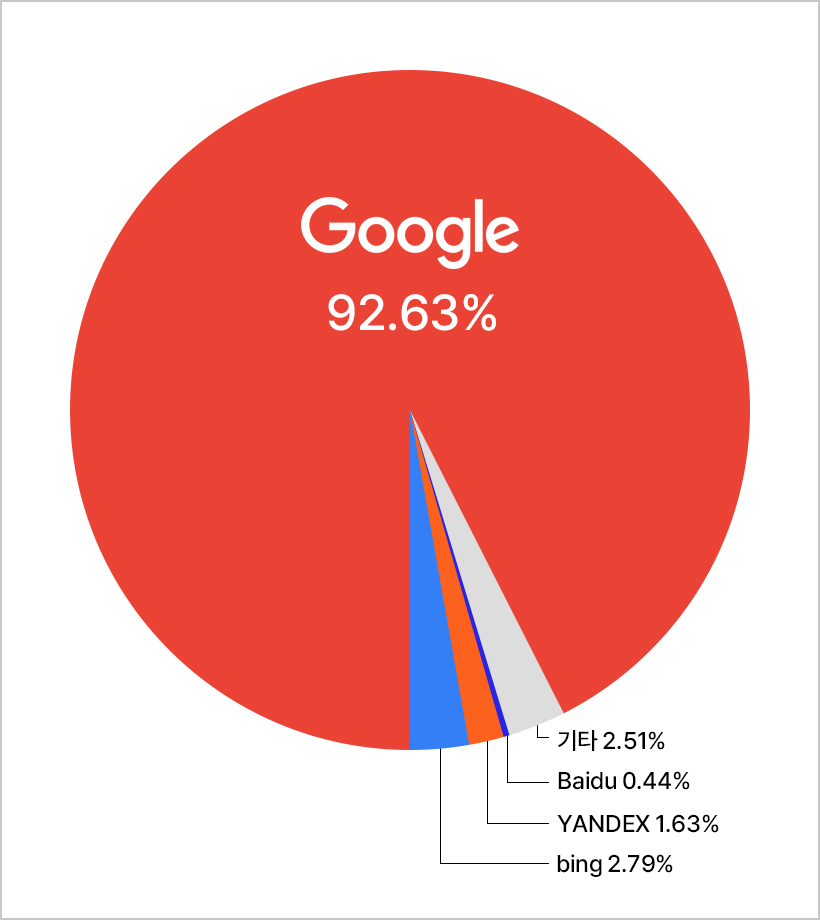
구글이 굳이 MS의 도발에 넘어갈 필요는 없다. 통계를 내는 사이트에 따라 다르지만 빙 검색이 10%를 넘은 적도, 구글 검색이 80% 이하로 떨어진 적도 없다. 그럼에도 구글은 민감하게 대응했지만 오히려 결과는 좋지 않았다. 구글이 만든 챗GPT로 사랑받을 줄 알았던 ‘바드’는 출시와 함께 기능을 시연하는 이벤트에서 오답을 말하는 바람에 망신을 당했다.
구글이 체면을 구기는 사이 MS는 자기가 잘하는 일에 생성 AI를 더했다. MS 오피스에는 '코파일럿'이란 이름으로 생성 AI를 내장하기로 했다. 그리고 빙 검색에 '빙 이미지 크리에이터'란 이름으로 달리2를 기반으로 그림을 그려주는 기능까지 더했다.

구글 I/O 2023 기조연설은 이를 꽉 깨문 구글이 준비한 반격이었다. 하지만 MS는 구글의 행사에 계속 초를 치려고 했다. 구글 I/O 이틀 전에 빙 챗봇에 어떻게 광고를 실을 건지 발표했고 하루 전에는 빙 챗봇을 대기 없이 누구나 쓸 수 있도록 공개했다. 구글은 이런 모습을 지켜보다가 I/O 기조연설에서 작심한 듯 준비한 모든 걸 쏟아냈다.
먼저 대형 언어 모델 팜(PaLM)을 팜2로 업그레이드했다. 매개 변수를 무려 5,300억 개나 사용하는 모델이다. 이에 기반한 AI 챗봇 바드도 세계 180개국에서 쓸 수 있게 했다. 한국어와 일본어 지원도 더해졌다. 몇 년 전 정보에서 멈춘 챗GPT와는 달리 최신 정보를 바로바로 반영해 알려주는 것도 장점이다.
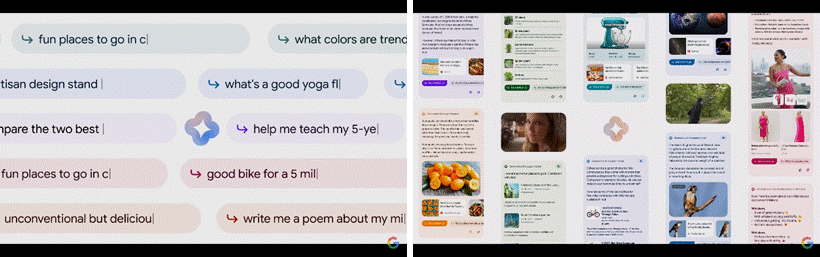
AI를 활용해 정리한 정보를 먼저 표시하고 밑에 관련 링크나 제품을 표시하는 식으로 검색 기능도 업그레이드했다. ‘관점’이란 이름으로 블로그나 짧은 영상, 커뮤니티의 글만 따로 모아 볼 수도 있게 하고, 간단히 클릭 한 번으로 질문이나 검색을 이어 나가도록 돕는 기능도 있다. MS와 마찬가지로 구글 문서 도구 등에 바드를 삽입해 이메일 답장이나 문서 초안을 간단히 만들 수 있게 돕는다.
검색 AI 전쟁의 미래
이 싸움은 사실 검색 엔진을 둘러싼 단순한 주도권 다툼이 아니라, 사용자 데이터 확보와 더불어 클라우드 서비스와 광고비를 놓고 벌이는 경쟁이다. 이제 막 시작됐기에 누가 이길지를 점치는 것은 쉽지 않다. 이럴 때는 역시 더 많은 사람과 회사를 같은 편, 같은 생태계에 끌어들이는 쪽이 유리하다. 구글이 만든 광고 수익 공유 모델로 인해 얼마나 많은 사람들이 유튜브에 뛰어들었고, 블로거가 됐는지를 생각하면 된다. 구글은 모자란 이미지 생성 기술을 위해 어도비와 손잡았고, 갤럭시 폰에 탑재되는 스마트 키보드 앱 ‘스위프트키’에 MS의 빙을 기본 적용하기로 했다.

생성 AI를 준비하고 있는 회사가 MS와 구글만 있는 것도 아니다. 이미지 생성 AI 대결에서 오픈 소스인 스테이블 디퓨전이 실제 변화를 주도한 것처럼, 챗GPT 같은 거대 언어 모델에도 오픈 소스가 존재한다. 메타에서 발표한 LLaMA(Large Language Model Meta AI) 모델이 대표적이다. 학계와 연구 기관이 무료로 쓸 수 있게 준비했지만 누군가가 유출해 많은 사람이 내려받았다.
그러자 곧 활용이 시작됐다. 한 달도 지나지 않아 스마트폰에서 실행되는 모델, 개인 PC에서 실행되는 모델이 등장했다. 아직 기능은 미약하지만 명확한 사용 목적만 생기면 또 어떤 변화가 일어날지 모른다. 반대로 오픈 소스 모델에서 쓰일 곳이 명확하게 생기지 않는다면, 지금 AI 검색 전쟁은 언제 그랬냐는 듯이 조용해질지도 모른다. 쓸 곳도 없는데 이 비싼 AI 모델을 계속 유지할 명분이 적다.
한국어에 특화된 AI 모델이 어떻게 발전할지도 변수다. 구글 바드는 공식적으로 한국어를 지원하지만 챗GPT 같은 경우엔 한국어로 물을 때와 영어로 물을 때 답변의 질이 다르다. 한국어 데이터를 많이 습득하지 못한 탓이다. 반면 우리나라 회사에는 기회다. 네이버가 오는 7월 내놓을 ‘서치GPT(가칭, 하이퍼클로바X 기반)’와 카카오가 올해 하반기 내놓을 ‘코챗GPT’가 그런 제품이다. GPT의 장점을 가지면서 한국어로 된 정보에 더 능통할 것으로 기대된다.
검색 AI 전쟁은 크게 MS와 구글이 주도하고 있지만 물밑에선 아마존, 메타, 네이버, 카카오 등 애플을 제외한 주요 기술 기업이 모두 참전하는 모양새다. 아직은 초기이기에 활용 용도를 찾는데 분주하지만 쓸 곳이 분명해지면 정말 뜨거운 격전이 벌어질 예정이다. 검색 엔진 시장에 앞으로 어떤 변화가 있을지 기대해 보자.

필자 / 이요훈 IT 칼럼니스트
전 한양대 미래융합학과 IAB 자문교수
전 한국과학기술영향평가 전문위원
※ 이 칼럼은 해당 필진의 개인적 소견이며 삼성디스플레이 뉴스룸의 입장이나 전략을 담고 있지 않습니다.
