

“열려라, 참깨!”
‘알리바바와 40인의 도둑들’의 주문을 기억하시나요? 음성 명령어의 원형이라고 할 만한 이 장면은 오랜 시간 후에 실제로 구현되었습니다. 1952년 미국 벨 연구소(Bell Labs)가 최초로 개발한 오드리(Audrey)는 음성인식 서비스의 효시로, 그 후 비약적인 발전을 거듭해 왔는데요. 오늘날 일상적으로 사용하는 음성 키오스크 주문기, 시리와 인공지능 스피커, 내비게이션 등 음성인식 기술은 인간과 기계를 잇는 일상적 가교로 작용하고 있습니다. 음성인식 기술은 인간의 편리한 삶을 가능하게 해주지만, 언어별로 적용 가능한 범위가 크게 다른 양극화 현상이 존재합니다. 국내외 플레이어 동향과 기술의 발전상, 향후 해결 과제를 한 번 알아볼까요?
글. MIT Technology Review 편집팀
기술과 서비스의 각축장, 음성인식 시장의 확장
최근 코로나 팬데믹 기간을 거치면서 음성 기술의 중요성이 훨씬 더 커졌습니다. 매거진 <음성 기술> 최신호에 따르면 음성인식 시장의 규모는 2025년까지 268억 달러(약 31조 7,000억 원)에 달할 것으로 전망하고 있으며 향후 발전 가능성 또한 높습니다.
국내는 주요 가전업체와 통신사, 플랫폼 기업이 시장을 주도하고 있는데요. 주요 기기와 서비스로는 ▲삼성 ‘빅스비’ ▲LG ‘Q보이스’ ▲SK텔레콤 ‘누구’ ▲KT ‘기가지니’ ▲네이버 ‘클로바’ ▲카카오 ‘카카오’ 등이 있습니다. 국내 음성 AI 플랫폼은 한국어에 특화된 음성 인식∙합성 성능과 IPTV 셋톱박스 기능, 검색, 팟캐스트나 음악 스트리밍 등 국내 인터넷∙모바일 서비스와의 연동을 강조하고 있습니다.
반면 글로벌 음성 AI 시장에 빠르게 진입한 기업은 대부분 자이언트 테크 기업인데요. 가장 먼저 출시된 플랫폼이 애플의 '시리'입니다. 애플은 2011년 아이폰4S에 시리를 탑재하면서 음성 AI 시장경쟁의 신호탄을 쏘아 올렸고, 이어 아마존이 2014년 스마트스피커 에코(Echo)와 사용자의 음성을 분석해 명령을 수행하는 플랫폼 ‘알렉사’를 선보였습니다.
강력한 검색엔진과 방대한 사용자 데이터를 확보한 구글은 2012년 구글 나우(Google Now)를 출시했으며 2015년 공개한 AI 음성 비서 구글 어시스턴트와 통합 중입니다. 이어 무서운 성장세를 보이는 바이두가 2017년 ‘두어’ 플랫폼을 출시하며 새롭게 경쟁에 뛰어들었습니다. 이처럼 음성인식 시장은 빅 테크 기업들의 기술력과 다양한 플랫폼 서비스가 함께 경쟁하며 점점 더 시장이 확장되고 있는 추세입니다.

▲ 음성 AI 시장의 주요 플레이어들
음성인식 기술이 작동하는 방식

현재 우리나라는 네이버와 카카오엔터프라이즈를 필두로 음성인식 기술 발전에 박차를 가하고 있습니다. 네이버의 경우 파라미터(매개변수)가 2040억개인 초거대 AI ‘하이퍼클로바’를 개발해 자사 서비스에 적용하고 있습니다(조성준, “디지털 혁신 가져올 ‘AI’…딥러닝의 시대가 온다”, 매일일보, 2022, 06.26). 카카오의 경우 지난 1월부터 AI 기업용 음성 인식-변환 모델 ‘커스텀 STT(Custom Speech-to-Text)’를 공개했습니다(김미정, “카카오엔터프라이즈, 기업용 AI음성 인식-변환 모델 ‘커스텀STT’공개, 2022, 01.25).
해당 기업이 직접 단어와 패턴을 추가하면, 가장 적합한 AI 모델을 빠른 시간 내 자동으로 만들어주는 시스템으로, 정확도는 물론 시간과 비용을 대폭 절감할 수 있게 된 것이죠. 이처럼 한국 음성 AI의 경우, 한국어 특성상 단어가 아닌 형태소(의미를 가진 최소한의 단위) 단위로 인식이 이뤄지는데요. 말의 어미 등이 변하더라도 그 뜻을 잘 인식할 수 있도록 개발 중입니다. 업계에서는 연산 처리 속도와 정확도를 높여 방언 등 비정형 자연어를 효과적으로 인식하기 위한 딥러닝 기술을 활발하게 연구하고 있습니다.
그런데 음성 인식 기술로 작동되는 기계들은 사람처럼 우리의 말을 듣고 이해해 대답하는 것이 아니라 완전히 다른 과정으로 진행되는데요. 시리나 빅스비 등 가상 비서들은 딥러닝 기반의 자연어 처리(NLP) 기술을 통해 사람의 언어를 이해합니다. 수많은 자연어 데이터를 처리하고 분석하기 위해 복잡한 과정을 거치기 마련인데요.
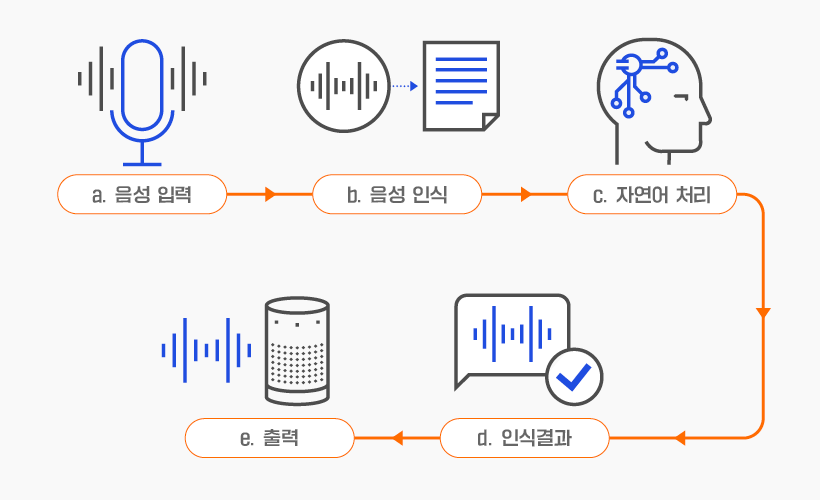
a. 음성 입력: 호출어와 함께 스마트폰의 가상 비서나 AI 스피커에 명령어 입력
b. 음성 인식: 기계는 STT (speech-to-text) 기술을 통해 사용자의 음성을 텍스트로 변환
c. 자연어 처리 (Natural Language Prosessing): 기계는 NLP 기술을 통해 데이터 분석 및 이해
d. 인식 결과: TTS (text-to-speech) 기술로 처리한 텍스트를 오디오로 변환
e. 출력: 변환된 오디오를 사용자에 송출
이 과정은 비교적 간단해 보이지만, 기계의 입장에서 인간의 언어는 이해하기 매우 어려운 영역입니다. 기계가 인간의 언어를 이해하기 위해서는 컴퓨터공학, 인공지능, 언어학 등이 복합적으로 작용하기 때문에 NLP(자연어 처리) 기술은 매우 복잡하고 정교합니다. 그렇기 때문에 앞으로 AI 음성 기술의 발전에 귀추를 주목해야 하는 것입니다.
눈부시게 발전한 자연어 처리 기술 및 서비스

▲ 출처: 유튜브 <What is NLP (Natural Language Processing)?>
현재 음성인식 기술 분야에서 가장 주목받고 있는 플레이어는 누구일까요? 바로 메타플랫폼(이하 메타)에서 내놓은 AI 자기학습 알고리즘 ‘데이터-투-백(Data2vec)’입니다. 세계 최초로 음성은 물론 이미지, 텍스트를 동시에 처리할 수 있는 자기학습(self-supervised) 인공지능(AI) 알고리즘이기 때문인데요. 메타 AI의 이 모델은 음성, 이미지, 텍스트 등의 각 분야에서만 성능을 낼 수밖에 없었던 기존 모델 방식의 패러다임을 완전히 바꿨습니다. 주변을 관찰하면서 사람처럼 학습하는 인공지능이 목전으로 다가온 것입니다! 이 알고리즘은 자기학습으로 훈련하기 때문에 복잡한 문제를 스스로 해결할 수 있는 음성인식 기반 기술로 진화하고 있습니다.
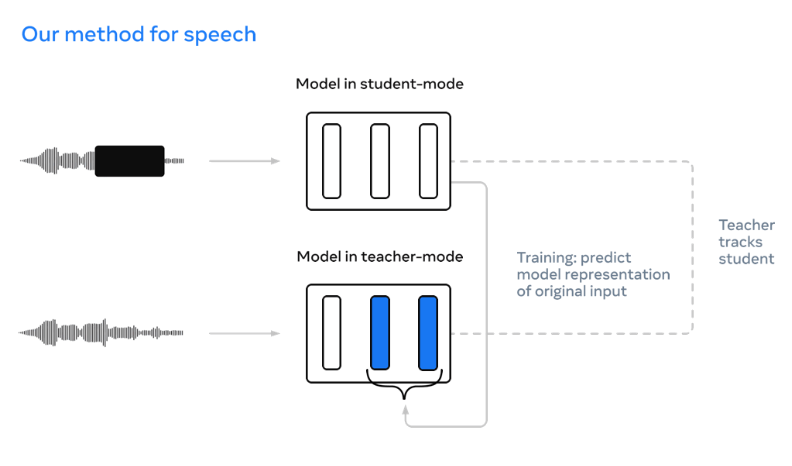
▲ 메타플랫폼이 음성을 인식하는 기술 (출처: 메타AI 홈페이지)
구글이 출시한 서비스도 이용자 의도를 보다 잘 이해하는 방향으로 진화하고 있습니다. AI 음성비서 서비스 ‘구글어시스턴트'는 인간의 언어습관을 섬세하게 인식할 수 있도록 업데이트됐는데요. 구글은 이용자의 ‘시선’을 인식해 별도의 명령어 없이도 구글 어시스턴트를 실행하는 ‘룩 앤 톡(Look and Talk)’ 서비스를 제공합니다. 이는 구글이 카메라를 통해 100개 이상의 시선 신호를 분석하는 기술을 어시스턴트에 녹여낸 결과인데요. 한 마디로 ‘눈짓’만으로 명령을 실행할 수 있게 된 셈입니다. 이를 통해 AI비서와 이용자 간 보다 유연하고 자연스러운 대화가 가능해지게 됐으며 대화에서 발생하는 ‘머뭇거림'을 인식하고, 때로는 명령을 기다려줄 수 있는 ‘스피치 모드(Speech modes)’도 장착했습니다.
인공지능은 언어의 장벽을 넘을 수 있을까
하지만 음성인식 AI가 어려움을 겪는 영역은 따로 있습니다. 각 나라마다 사용하는 각기 다른 언어를 인식하는 문제입니다. 특히 모로코어, 알제리어, 이집트어, 수단어 등 아랍어의 다양한 방언을 사용하는 사람들은 이러한 음성인식 기술의 혜택에서 가장 멀리 떨어져 있습니다. 30개에 달하는 아랍어 방언은 지역마다 세분화되어 발전했고, 어떤 방언들은 이미 서로 이해할 수 없을 정도로 달라져 있기 때문입니다. 여기에 핀란드어, 몽골어, 나바호어 등 형태학적으로 매우 복잡한 언어를 모국어로 하는 사람들 역시 이러한 기술 발전에서 소외되고 있는 실정입니다.
기계 번역(Machine Translation) 시스템은 빠르게 개선되고 있지만, 여전히 많은 양의 텍스트 데이터로부터 학습하는 것에 크게 의존하고 있기 때문에, 일반적으로 저자원 언어, 즉 학습 데이터가 부족한 언어에는 제대로 작동하지 않습니다. 앱이나 웹에서 일상적인 번역이 제공되는 언어는 우리말, 영어, 중국어 또는 스페인어 등에 불과합니다. 여전히 대부분의 사람들은 모국어로 세계와 소통할 수 없는 현실입니다.

▲ 출처: 유튜브 <Teaching AI to translate 100s of spoken and written languages in real time>
사실 우리는 한국어를 사용하고 있는 덕분에 엄청난 기술의 진보를 누리고 있습니다. 현재까지 대부분의 음성인식 도구들이 영어를 비롯한 소수의 몇 개 언어에 국한되어 있기 때문인데요. 모쪼록 음성인식 기술이 더욱 발전해, 국경과 언어의 장벽을 허물 수 있는 날이 빨리 오기를 바랍니다.

